Troubleshooting#
Why does my job not run faster when using more nodes and/or cores?#
Requesting more resources for your job, more specifically using multiple cores and/or nodes, does not automatically imply that your job will run faster. There are various factors that determine to what extent these extra resources can be used and how efficiently they can be used. More information on this in the subsections below.
Using multiple cores#
When you want to speed up your jobs by requesting multiple cores, you also need to use software that is actually capable of using them (and use them efficiently, ideally). Unless a particular parallel programming paradigm like OpenMP threading (shared memory) or MPI (distributed memory) is used, software will run sequentially (on a single core).
To use multiple cores, the software needs to be able to create, manage, and synchronize multiple threads or processes. More on how to implement parallelization for you exact programming language can be found online. Note that when using software that only uses threads to use multiple cores, there is no point in asking for multiple nodes, since with a multi-threading (shared memory) approach you can only use the resources (cores, memory) of a single node.
Even if your software is able to use multiple cores, maybe there is no point in going beyond a single core or a handful of cores, for example because the workload you are running is too small or does not parallelize well. You can test this by increasing the amount of cores step-wise, and look at the speedup you gain. For example, test with 2, 4, 16, a quarter of, half of, and all available cores.
Other reasons why using more cores may not lead to a (significant) speedup include:
-
Overhead: When you use multi-threading (OpenMP) or multi-processing (MPI), you should not expect that doubling the amount of cores will result in a 2x speedup. This is due to the fact that time is needed to create, manage and synchronize the threads/processes. When this "bookkeeping" overhead exceeds the time gained by parallelization, you will not observe any speedup (or even see slower runs). For example, this can happen when you split your program in too many (tiny) tasks to run in parallel - creating a thread/process for each task may even take longer than actually running the task itself.
-
Amdahl's Law is often used in parallel computing to predict the maximum achievable (theoretical) speedup when using multiple cores. It states that "the overall performance improvement gained by optimizing a single part of a system is limited by the fraction of time that the improved part is actually used". For example, if a program needs 20 hours to complete using a single core, but a one-hour portion of the program can not be parallelized, only the remaining 19 hours of execution time can be sped up using parallelization. Regardless of how many cores are devoted to a parallelized execution of this program, the minimum execution time is always more than 1 hour. So when you reach this theoretical limit, using more cores will not help at all to speed up the computational workload.
-
Resource contention: When two or more threads/processes want to access the same resource, they need to wait on each other - this is called resource contention. As a result, 1 thread/process will need to wait until the other one is finished using that resource. When each thread uses the same resource, it will definitely run slower than if it doesn't need to wait for other threads to finish.
-
Software limitations: It is possible that the software you are using is just not really optimized for parallelization. An example of a software that is not really optimized for multi-threading is Python (although this has improved over the years). This is due to the fact that in Python threads are implemented in a way that multiple threads can not run at the same time, due to the global interpreter lock (GIL). Instead of using multi-threading in Python to speedup a CPU bound program, you should use multi-processing instead, which uses multiple processes (multiple instances of the same program) instead of multiple threads in a single program instance. Using multiple processes can speed up your CPU bound programs a lot more in Python than threads can do, even though they are much less efficient to create. In other programming languages (which don't have a GIL), you would probably still want to use threads.
-
Affinity and core pinning: Even when the software you are using is able to efficiently use multiple cores, you may not see any speedup (or even a significant slowdown). This could be due to threads or processes that are not pinned to specific cores and keep hopping around between cores, or because the pinning is done incorrectly and several threads/processes are being pinned to the same core(s), and thus keep "fighting" each other.
-
Lack of sufficient memory: When there is not enough memory available, or not enough memory bandwidth, it is likely that you will not see a significant speedup when using more cores (since each thread or process most likely requires additional memory).
There is more info on running multi-core workloads on the HPC-UGent infrastructure.
Using multiple nodes#
When trying to use multiple (worker)nodes to improve the performance of your workloads, you may not see (significant) speedup.
Parallelizing code across nodes is fundamentally different from leveraging multiple cores via multi-threading within a single node.
The scalability achieved through multi-threading does not extend seamlessly to distributing computations across multiple nodes.
This means that just changing #PBS -l nodes=1:ppn=10 to #PBS -l nodes=2:ppn=10 may only increase the waiting time to get your job running (because twice as many resources are requested), and will not improve the execution time.
Actually using additional nodes is not as straightforward as merely asking for multiple nodes when submitting your job. The resources on these additional nodes often need to discovered, managed, and synchronized. This introduces complexities in distributing work effectively across the nodes. Luckily, there exist some libraries that do this for you.
Using the resources of multiple nodes is often done using a Message Passing Interface (MPI) library. MPI allows nodes to communicate and coordinate, but it also introduces additional complexity.
We have an example of how you can make beneficial use of multiple nodes.
You can also use MPI in Python, some useful packages that are also available on the HPC are:
We advise to maximize core utilization before considering using multiple nodes. Our infrastructure has clusters with a lot of cores per node so we suggest that you first try to use all the cores on 1 node before you expand to more nodes. In addition, when running MPI software we strongly advise to use our mympirun tool.
How do I know if my software can run in parallel?#
If you are not sure if the software you are using can efficiently use multiple cores or run across multiple nodes, you should check its documentation for instructions on how to run in parallel, or check for options that control how many threads/cores/nodes can be used.
If you can not find any information along those lines, the software you are using can probably only use a single core and thus requesting multiple cores and/or nodes will only result in wasted resources.
Walltime issues#
If you get from your job output an error message similar to this:
=>> PBS: job killed: walltime <value in seconds> exceeded limit <value in seconds>
This occurs when your job did not complete within the requested walltime. See section on Specifying Walltime for more information about how to request the walltime.
Out of quota issues#
Sometimes a job hangs at some point or it stops writing in the disk. These errors are usually related to the quota usage. You may have reached your quota limit at some storage endpoint. You should move (or remove) the data to a different storage endpoint (or request more quota) to be able to write to the disk and then resubmit the jobs.
Another option is to request extra quota for your VO to the VO moderator/s. See section on Pre-defined user directories and Pre-defined quotas for more information about quotas and how to use the storage endpoints in an efficient way.
Issues connecting to login node#
If you are confused about the SSH public/private key pair concept, maybe the key/lock analogy in How do SSH keys work? can help.
If you have errors that look like:
vsc40000@login.hpc.ugent.be: Permission denied
or you are experiencing problems with connecting, here is a list of things to do that should help:
-
Keep in mind that it can take up to an hour for your VSC account to become active after it has been approved; until then, logging in to your VSC account will not work.
-
Make sure you are connecting from an IP address that is allowed to access the VSC login nodes, see section Connection restrictions for more information.
-
Please double/triple check your VSC login ID. It should look something like vsc40000: the letters
vsc, followed by exactly 5 digits. Make sure it's the same one as the one on https://account.vscentrum.be/. -
You previously connected to the HPC from another machine, but now have another machine? Please follow the procedure for adding additional keys in section Adding multiple SSH public keys. You may need to wait for 15-20 minutes until the SSH public key(s) you added become active.
-
When using an SSH key in a non-default location, make sure you supply the path of the private key (and not the path of the public key) to
ssh.id_rsa.pubis the usual filename of the public key,id_rsais the usual filename of the private key. (See also section Connect) -
If you have multiple private keys on your machine, please make sure you are using the one that corresponds to (one of) the public key(s) you added on https://account.vscentrum.be/.
-
Please do not use someone else's private keys. You must never share your private key, they're called private for a good reason.
If you've tried all applicable items above and it doesn't solve your problem, please contact hpc@ugent.be and include the following information:
Please add -vvv as a flag to ssh like:
ssh -vvv vsc40000@login.hpc.ugent.be
and include the output of that command in the message.
Issues reaching servers from HPC infrastructure#
If you have to reach license servers from HPC-UGent infrastructure systems or you
have to directly load some database here, then it might not work
(you will get errors like Network connection timed out or Network connection refused).
Our firewall rules are quite strict, we only allow outging ports 22 (SSH protocol), 80 (HTTP protocol), and 443 (HTTPS protcol), so if your download or license server requires other ports, then we should make a modification in our firewall settings. For this, please contact us via hpc@ugent.be, and send the destination IP and ports. (We only open our firewall for static IP addresses).
Take into account that the other end may also has a firewall, or that the license server may restrict the incoming IP addresses. In this case you need the outgoing IP address of our systems, which is either of:
157.193.240.251(hostnamenathpca001.ugent.be), or157.193.241.251(hostnamenathpcb001.ugent.be)
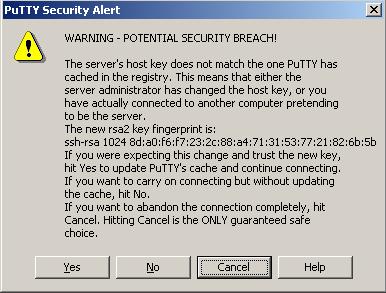
Security warning about invalid host key#
If you get a warning that looks like the one below, it is possible that someone is trying to intercept the connection between you and the system you are connecting to. Another possibility is that the host key of the system you are connecting to has changed.
You will need to verify that the fingerprint shown in the dialog matches one of the following fingerprints:
- ssh-rsa 2048 10:2f:31:21:04:75:cb:ed:67:e0:d5:0c:a1:5a:f4:78
- ssh-rsa 2048 SHA256:W8Wz0/FkkCR2ulN7+w8tNI9M0viRgFr2YlHrhKD2Dd0
- ssh-ed25519 255 19:28:76:94:52:9d:ff:7d:fb:8b:27:b6:d7:69:42:eb
- ssh-ed25519 256 SHA256:8AJg3lPN27y6i+um7rFx3xoy42U8ZgqNe4LsEycHILA
- ssh-ecdsa 256 e6:d2:9c:d8:e7:59:45:03:4a:1f:dc:96:62:29:9c:5f
- ssh-ecdsa 256 SHA256:C8TVx0w8UjGgCQfCmEUaOPxJGNMqv2PXLyBNODe5eOQ
Do not click "Yes" until you verified the fingerprint. Do not press "No" in any case.
If the fingerprint matches, click "Yes".
If it doesn't (like in the example) or you are in doubt, take a screenshot, press "Cancel" and contact hpc@ugent.be.
Note: it is possible that the ssh-ed25519 fingerprint starts with ssh-ed25519 255
rather than ssh-ed25519 256 (or vice versa), depending on the PuTTY version you are using.
It is safe to ignore this 255 versus 256 difference, but the part after should be
identical.
DOS/Windows text format#
If you get errors like:
$ qsub fibo.pbs
qsub: script is written in DOS/Windows text format
or
sbatch: error: Batch script contains DOS line breaks (\r\n)
It's probably because you transferred the files from a Windows computer.
See the section about dos2unix in Linux tutorial to fix this error.
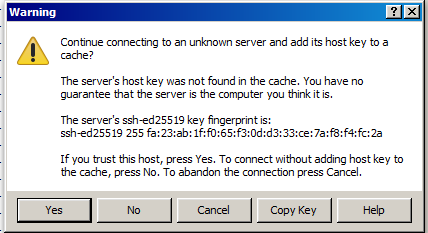
Warning message when first connecting to new host#
If it does, type yes. If it doesn't, please contact support: hpc@ugent.be.
The first time you make a connection to the login node, a Security Alert will appear and you will be asked to verify the authenticity of the login node.
Make sure the fingerprint in the alert matches one of the following:
- ssh-rsa 2048 10:2f:31:21:04:75:cb:ed:67:e0:d5:0c:a1:5a:f4:78
- ssh-rsa 2048 SHA256:W8Wz0/FkkCR2ulN7+w8tNI9M0viRgFr2YlHrhKD2Dd0
- ssh-ed25519 255 19:28:76:94:52:9d:ff:7d:fb:8b:27:b6:d7:69:42:eb
- ssh-ed25519 256 SHA256:8AJg3lPN27y6i+um7rFx3xoy42U8ZgqNe4LsEycHILA
- ssh-ecdsa 256 e6:d2:9c:d8:e7:59:45:03:4a:1f:dc:96:62:29:9c:5f
- ssh-ecdsa 256 SHA256:C8TVx0w8UjGgCQfCmEUaOPxJGNMqv2PXLyBNODe5eOQ
If it does, press Yes, if it doesn't, please contact hpc@ugent.be.
Note: it is possible that the ssh-ed25519 fingerprint starts with ssh-ed25519 255
rather than ssh-ed25519 256 (or vice versa), depending on the PuTTY version you are using.
It is safe to ignore this 255 versus 256 difference, but the part after should be
identical.
Memory limits#
To avoid jobs allocating too much memory, there are memory limits in place by default. It is possible to specify higher memory limits if your jobs require this.
Note
Memory is not the same as storage. Memory or RAM is used for temporary, fast access to data when the program is running, while storage is used for long-term data retention. If you are running into problems because you reached your storage quota, see Out of quota issues.
How will I know if memory limits are the cause of my problem?#
If your program fails with a memory-related issue, there is a good chance it failed because of the memory limits and you should increase the memory limits for your job.
Examples of these error messages are: malloc failed, Out of memory,
Could not allocate memory or in Java:
Could not reserve enough space for object heap. Your program can also
run into a Segmentation fault (or segfault) or crash due to bus
errors.
You can check the amount of virtual memory (in Kb) that is available to
you via the ulimit -v command in your job script.
How do I specify the amount of memory I need?#
See Generic resource requirements to set memory and other requirements, see Specifying memory requirements to finetune the amount of memory you request.
Module conflicts#
Modules that are loaded together must use the same toolchain version or common dependencies. In the following
example, we try to load a module that uses the GCCcore-13.3.0 toolchain
together with one that uses the GCCcore-13.2.0 toolchain:
$ module load Python/3.12.3-GCCcore-13.3.0
$ module load Pillow/10.2.0-GCCcore-13.2.0
Lmod has detected the following error: A different version of the 'GCCcore' module is already loaded (see output of 'ml').
You should load another 'Pillow' module for that is compatible with the currently loaded version of 'GCCcore'.
Use 'ml spider Pillow' to get an overview of the available versions.
If you don't understand the warning or error, contact the helpdesk at hpc@ugent.be
While processing the following module(s):
Module fullname Module Filename
--------------- ---------------
Pillow/10.2.0-GCCcore-13.2.0 /apps/gent/RHEL8/zen2-ib/modules/all/Pillow/10.2.0-GCCcore-13.2.0.lua
This resulted in an error because we tried to load two modules with different
versions of the GCCcore toolchain.
To fix this, check if there are other versions of the modules you want to load
that have the same version of common dependencies. You can list all versions of
a module with module avail: for Pillow, this command is module avail Pillow.
As a rule of thumb, toolchains in the same row are compatible with each other:
| GCCcore-14.3.0 | GCC-14.3.0 | gfbf-2025b/gompi-2025b | foss-2025b |
| GCCcore-14.3.0 | intel-compilers-2025.2.0 | iimkl-2025b/iimpi-2025b | intel-2025b |
| GCCcore-14.2.0 | GCC-14.2.0 | gfbf-2025a/gompi-2025a | foss-2025a |
| GCCcore-14.2.0 | intel-compilers-2025.1.1 | iimkl-2025a/iimpi-2025a | intel-2025a |
| GCCcore-13.3.0 | GCC-13.3.0 | gfbf-2024a/gompi-2024a | foss-2024a |
| GCCcore-13.3.0 | intel-compilers-2024.2.0 | iimkl-2024a/iimpi-2024a | intel-2024a |
| GCCcore-13.2.0 | GCC-13.2.0 | gfbf-2023b/gompi-2023b | foss-2023b |
| GCCcore-13.2.0 | intel-compilers-2023.2.1 | iimkl-2023b/iimpi-2023b | intel-2023b |
| GCCcore-12.3.0 | GCC-12.3.0 | gfbf-2023a/gompi-2023a | foss-2023a |
| GCCcore-12.3.0 | intel-compilers-2023.1.0 | iimkl-2023a/iimpi-2023a | intel-2023a |
| GCCcore-12.2.0 | GCC-12.2.0 | gfbf-2022b/gompi-2022b | foss-2022b |
| GCCcore-12.2.0 | intel-compilers-2022.2.1 | iimkl-2022b/iimpi-2022b | intel-2022b |
| GCCcore-11.3.0 | GCC-11.3.0 | gfbf-2022a/gompi-2022a | foss-2022a |
| GCCcore-11.3.0 | intel-compilers-2022.1.0 | iimkl-2022a/iimpi-2022a | intel-2022a |
| GCCcore-11.2.0 | GCC-11.2.0 | gfbf-2021b/gompi-2021b | foss-2021b |
| GCCcore-11.2.0 | intel-compilers-2021.4.0 | iimkl-2021b/iimpi-2021b | intel-2021b |
| GCCcore-10.3.0 | GCC-10.3.0 | gfbf-2021a/gompi-2021a | foss-2021a |
| GCCcore-10.3.0 | intel-compilers-2021.2.0 | iimkl-2021a/iimpi-2021a | intel-2021a |
| GCCcore-10.2.0 | GCC-10.2.0 | gfbf-2020b/gompi-2020b | foss-2020b |
| GCCcore-10.2.0 | iccifort-2020.4.304 | iimkl-2020b/iimpi-2020b | intel-2020b |
Example
we could load the following modules together:
ml XGBoost/1.7.2-foss-2022a
ml scikit-learn/1.1.2-foss-2022a
ml cURL/7.83.0-GCCcore-11.3.0
ml JupyterNotebook/6.4.0-GCCcore-11.3.0-IPython-8.5.0
Another common error is:
$ module load cluster/donphan
Lmod has detected the following error: A different version of the 'cluster' module is already loaded (see output of 'ml').
If you don't understand the warning or error, contact the helpdesk at hpc@ugent.be
This is because there can only be one cluster module active at a time.
The correct command is module swap cluster/donphan. See also Specifying the cluster on which to run.
Illegal instruction error#
Running software that is incompatible with host#
When running software provided through modules (see Modules), you may run into errors like:
$ module swap cluster/donphan
The following have been reloaded with a version change:
1) cluster/doduo => cluster/donphan 3) env/software/doduo => env/software/donphan
2) env/slurm/doduo => env/slurm/donphan 4) env/vsc/doduo => env/vsc/donphan
$ module load Python/3.12.3-GCCcore-13.3.0
$ python
Illegal instruction (core dumped)
When we swap to a different cluster, the available modules change so they work for that cluster. That means that if the cluster and the login nodes have a different CPU architecture, software loaded using modules might not work.
If you want to test software on the login nodes, make sure the
cluster/doduo module is loaded (with module swap cluster/doduo, see Specifying the cluster on which to run), since
the login nodes and doduo have the same CPU architecture.
If modules are already loaded, and then we swap to a different cluster, all our modules will get reloaded. This means that all current modules will be unloaded and then loaded again, so they'll work on the newly loaded cluster. Here's an example of how that would look like:
$ module load Python/3.12.3-GCCcore-13.3.0
$ module swap cluster/donphan
Due to MODULEPATH changes, the following have been reloaded:
1) GCCcore/13.3.0 7) binutils/2.42-GCCcore-13.3.0
2) OpenSSL/3 8) bzip2/1.0.8-GCCcore-13.3.0
3) Python/3.12.3-GCCcore-13.3.0 9) libffi/3.4.5-GCCcore-13.3.0
4) SQLite/3.45.3-GCCcore-13.3.0 10) libreadline/8.2-GCCcore-13.3.0
5) Tcl/8.6.14-GCCcore-13.3.0 11) ncurses/6.5-GCCcore-13.3.0
6) XZ/5.4.5-GCCcore-13.3.0 12) zlib/1.3.1-GCCcore-13.3.0
The following have been reloaded with a version change:
1) cluster/doduo => cluster/donphan
2) env/slurm/doduo => env/slurm/donphan
3) env/software/doduo => env/software/donphan
4) env/vsc/doduo => env/vsc/donphan
This might result in the same problems as mentioned above. When swapping
to a different cluster, you can run module purge to unload all modules
to avoid problems (see Purging all modules).
Multi-job submissions on a non-default cluster#
When using a tool that is made available via modules to submit jobs, for example Worker, you may run into the following error when targeting a non-default cluster:
$ wsub
/apps/gent/.../.../software/worker/.../bin/wsub: line 27: 2152510 Illegal instruction (core dumped) ${PERL} ${DIR}/../lib/wsub.pl "$@"
When executing the module swap cluster command, you are not only changing your session environment to submit
to that specific cluster, but also to use the part of the central software stack that is specific to that cluster.
In the case of the Worker example above, the latter implies that you are running the wsub command
on top of a Perl installation that is optimized specifically for the CPUs of the workernodes of that cluster,
which may not be compatible with the CPUs of the login nodes, triggering the Illegal instruction error.
The cluster modules are split up into several env/* "submodules" to help deal with this problem.
For example, by using module swap env/slurm/donphan instead of module swap cluster/donphan (starting from the default environment, the doduo cluster), you can update your environment to submit jobs to donphan, while still using the software installations that are specific to the doduo cluster (which are compatible with the login nodes since the doduo cluster workernodes have the same CPUs).
The same goes for the other clusters as well of course.
Tip
To submit a Worker job to a specific cluster, like the donphan interactive cluster for instance, use:
$ module swap env/slurm/donphan
$ module swap cluster/donphan
We recommend using a module swap cluster command after submitting the jobs.
This to "reset" your environment to a sane state, since only having a different env/slurm module loaded can also lead to some surprises if you're not paying close attention.